Refines prompts with parallel or sequential expert agents to boost cultural fidelity in text-to-video generation across mono- and cross-cultural prompts.
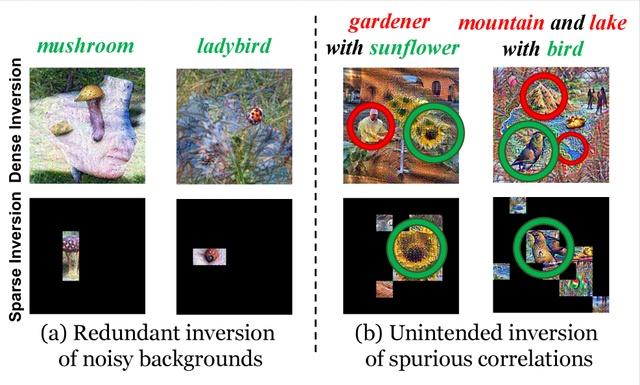
A novel sparse model inversion strategy enhances the efficiency of reconstructing original training data from Vision Transformers by selectively focusing on semantic foregrounds, thus accelerating inversion processes while preserving performance.