GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting
3D audio-driven talking face generation model using Gaussian Splatting for real-time rendering.
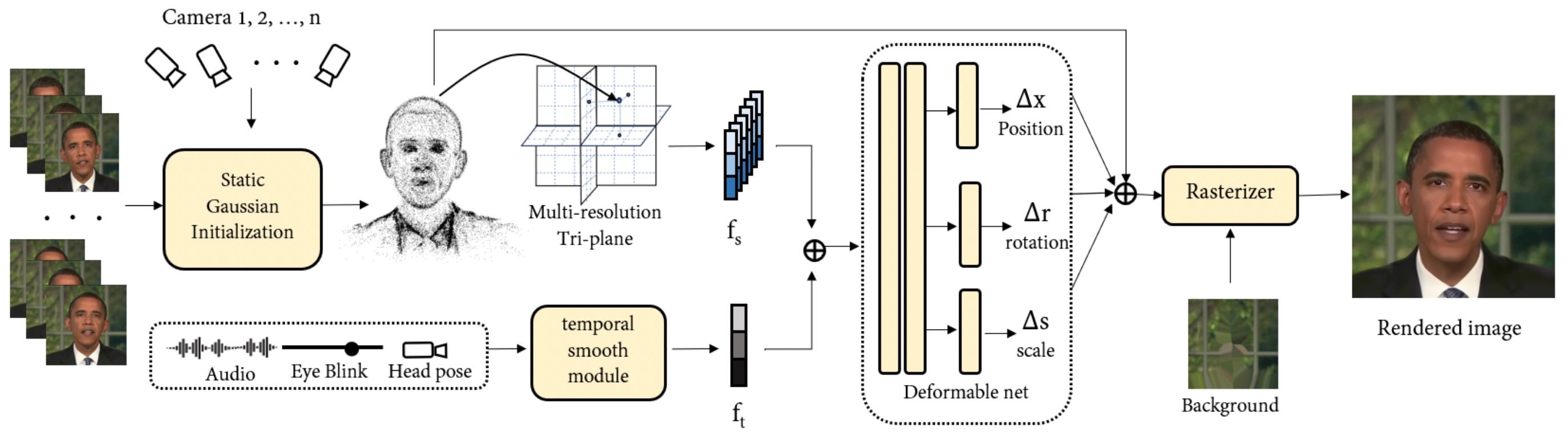
GSTalker is a novel framework which aims to enable rapid training and real-time rendering of audio-driven talking face generation through deformable Gaussian Splatting. The framework leverages 3D Gaussian Splatting, a technique previously used for rendering static and dynamic scenes, to generate talking faces driven by audio input. The main challenges addressed by GSTalker include how to incorporate audio information into the 3D Gaussian Splatting framework and how to optimize the efficiency of the model for audio-driven talking face generation.
With this framework, a 3-5 minute video of a specified portrait speaking in front of a fixed camera is used as training material. The camera pose is estimated by a face-tracker to simulate head motion, and audio signal processing involves feature extraction using a pre-trained ASR model. Semantic Parsing Method is utilized to segment the head, torso, and background parts. The methodology involves a static Gaussian initialization stage before training the deformation field to accelerate convergence in speech-driven speaker generation.
The implementation details include randomly initializing 10,000 Gaussian points within a cube, optimizing Gaussian properties individually in a static initialization phase, and optimizing Gaussian points and deformation field simultaneously. The framework utilizes an Adam optimizer with specific learning rates for different components and performs all experiments on a single RTX 3090 GPU. The proposed framework is compared to other baseline models in terms of image quality, lip synchronization, and efficiency, showcasing superior performance in various aspects.
Comments
None